Methodology
How We Ship Software Without AI Slop
I’ve spent the last three months building a software consultancy where nobody writes code.
Not “we write less code.” Not “AI helps us code faster.” Nobody writes code. Nobody reviews code line by line. AI does all of it.
When I tell people this, they have one of two reactions. The first is excitement — finally, someone who gets it. The second is horror — you’re shipping unreviewed AI code to production?
Both reactions miss the point.
We’re not reckless. We’re not vibe coding cowboys who throw prompts at Claude and ship whatever comes out. We built a system — a methodology — that prevents the thing everyone in the industry is worried about right now: AI slop.
This article is about that system. It’s long. It’s detailed. Because the details are where quality lives.
The Slop Problem Is Real
Let’s start by being honest about the problem.
AI slop is what happens when you generate code without structure. You ask ChatGPT to build you a dashboard, it produces something that looks impressive, you ship it. Three weeks later, a customer finds a bug. You ask the AI to fix the bug. It introduces two more. You ask it to fix those. The codebase becomes a layer cake of patches on top of patches, each one generated by an AI that had no memory of why the previous layers existed.
This is not a hypothetical. This is happening at scale right now, across the entire industry.
 The Synetica development flow: understanding flows into specification, specification drives AI execution, humans validate the outcome — not the code. View full size →
The Synetica development flow: understanding flows into specification, specification drives AI execution, humans validate the outcome — not the code. View full size →
CodeRabbit, an AI code review platform, published their 2026 report calling this the year enterprises must have a “harder conversation about quality, attribution, and governance” in AI-generated code. The productivity gains are real — but so is the tech debt accumulating silently underneath.
METR, a research organization, ran a rigorous randomized control trial in 2025. They found that experienced open-source developers using AI tools took 19% longer to complete tasks than developers working without AI. The uncomfortable part? Those developers believed they were 24% faster. They were wrong about both the direction and the magnitude of the effect.
How is this possible? Because AI makes you feel productive. Tokens are flowing. Code is appearing. Screens are filling up. But feeling productive and being productive are different things. The AI generates code quickly, but the human spends more time debugging, understanding, and fixing the AI’s output than they would have spent writing it themselves.
This is the slop trap. Speed without structure produces volume without quality.
But — and this is the part that matters — the same research also shows that specific teams, using specific workflows, are achieving extraordinary results. At Anthropic, 90% of the code for Claude Code was written by Claude Code itself. Boris Cherny, who leads the project, hasn’t personally written code in months. At a company called Strong DM, three engineers run what they call a “software factory.” Their two core principles:
- Code must not be written by humans.
- Code must not be reviewed by humans.
Three engineers. No one writes code. No one reviews code. Their system is a set of AI agents orchestrated by markdown specification files. The humans write specs and evaluate outcomes. The machines do everything in between.
So the question isn’t whether AI can produce quality code. It clearly can. The question is: what’s the difference between the teams that ship clean AI-generated code and the teams that ship slop?
The answer is the system around the AI, not the AI itself.
The Slop vs Quality Matrix:
| High Structure | Low Structure | |
|---|---|---|
| With AI | ✅ Quality at scale (Synetica) | ⚠️ AI Slop (vibe coding) |
| Without AI | 🐢 Quality but slow (traditional) | 💥 Chaos (cowboy coding) |
The question is never “should we use AI?” — it’s “do we have the structure to use AI well?”
Our System: The Seven Disciplines
We don’t call them “rules” or “best practices.” We call them disciplines, because that’s what they require. Each one is a deliberate choice to slow down at specific moments so that the overall process moves faster and produces better results.
Discipline 1: The Specification Is the Product
This is the foundation of everything we do at Synetica. It comes from a belief I’ve held for 15 years but couldn’t act on until AI made it practical: the value in software development was never in the coding. It was always in understanding the problem.
I wrote about this in detail in “The Code Is Not the Point Anymore.” The short version: for a decade, the Indonesian software industry (and honestly, the global industry) charged clients for developer hours. Six people, six months, a hundred million rupiah. But most of the value was delivered in the first two weeks — when someone actually sat down and understood what the client needed.
The remaining five and a half months? That was building. Slowly. With miscommunication. With requirements that drifted. With code reviews that caught syntax but missed intent.
AI just made the building part free. Which means the only thing worth paying for is the understanding.
At Synetica, we capture that understanding in what we call a Blueprint — a comprehensive specification that’s detailed enough for an AI agent to build from without ambiguity. A Blueprint includes:
- The actual problem — not what the client asked for, but what they actually need. These are often different. A client says “we need a CRM.” What they actually need is to stop losing leads between the sales call and the follow-up because three departments don’t talk to each other.
- System boundaries — what’s in scope, what’s explicitly out of scope, and what’s a future change request. This is critical because AI agents will happily build things you didn’t ask for if you don’t tell them not to.
- Data architecture — entities, relationships, constraints, validation rules. Not a rough sketch. A precise specification that leaves no room for the AI to make assumptions.
- User flows — step by step, including the edge cases that break most software. What happens when the user enters invalid data? What happens when two users try to approve the same thing simultaneously? What happens when the network drops?
- Acceptance criteria — measurable, testable conditions for “done.” Not “it should work.” But “when the user submits the form with valid data, the system should save the record and redirect to the dashboard within 2 seconds.”
- Testing strategy — what gets tested, how, and when. This is not an afterthought. It’s part of the spec.
Addy Osmani, a senior engineering leader at Google, describes this approach as “doing waterfall in 15 minutes” — a rapid structured planning phase that makes everything downstream cleaner. His observation: having a clear spec and plan means when you unleash the code generation, both the human and the AI know exactly what’s being built and why.
We’ve found that investing in the specification eliminates roughly 80% of the rework that typically comes from AI misunderstanding intent. The spec doesn’t slow us down. It’s the thing that makes everything else fast.
The discipline: No code is generated until the Blueprint is complete. No exceptions. If the spec has gaps, we go back to the client, not to the AI.
Discipline 2: Plan Big, Execute Fresh
This is the single most impactful technical discipline we practice, and it comes from a simple observation about how AI models work.
Ray Fernando, who runs multiple AI agents on a Mac Mini and has done extensive experimentation with context windows, identified what he calls the “hallucination threshold.” When a coding session exceeds roughly 50% of the model’s context window, the quality of output begins to degrade. The AI doesn’t get lazy — it gets distracted. All your previous conversation history, all the code it’s already generated, all the back-and-forth corrections — all of that becomes noise that competes with the actual task at hand.
Fernando demonstrated this dramatically: he had a planning session running at 93,000 tokens and was about to start implementing. He realized that if he started coding in the same session, the context would fill up immediately and the quality would tank. Instead, he exported his plan, started fresh sessions for each implementation task, and shipped full character sprite animations for five game characters in under one hour.
Same AI. Same model. Same capability. The only difference was fresh context.
Here’s how we apply this:
Phase 1: Planning (one deep session) We load the Blueprint, discuss architecture, make design decisions, and produce a structured task breakdown. This session can go long — 80K, 90K, even 100K tokens is fine because we’re thinking, not coding. The output of this session is a task plan document.
Phase 2: Execution (many fresh sessions) Each task from the plan gets its own fresh session. The AI receives only three things: the relevant section of the Blueprint, the relevant existing code, and the task description. Nothing else. No history of previous tasks. No conversation about the weather. Just clean, focused context.
This is counterintuitive. Most people think keeping the AI in one long session gives it “more context” and therefore better results. The opposite is true. A focused AI with 20K tokens of relevant context outperforms a distracted AI with 90K tokens of mixed context every time.
The discipline: Planning and execution happen in separate sessions. Every implementation task starts with a fresh context window. No exceptions.
Discipline 3: Tests Before Code (And AI Writes Both)
Test-driven development has been preached for decades. Most teams still don’t do it. The reason is that writing tests is tedious, and developers — being human — naturally gravitate toward the interesting work (writing the feature) and away from the boring work (writing the tests).
AI doesn’t have this bias. AI will happily write tests all day long.
The Superpowers framework, which has been gaining significant traction in the Claude Code and Cursor communities, formalizes this into a strict sequence:
1. Read the spec → 2. Generate tests from the spec → 3. Write code to pass the tests → 4. Verify tests pass → 5. Check against the original planThe critical insight is step 2: the AI writes tests directly from the specification, before it writes any implementation code. This means the tests reflect what the spec says should happen, not what the code happens to do. It’s the difference between “does this code work?” and “does this code do what we specified?”
Step 5 is equally important, and it comes from Rob Shocks’ work on development workflows. After each implementation task, the AI goes back to the original plan and verifies that the code matches the success criteria defined at the planning stage. This catches the most common failure mode in AI-assisted development: plan drift. AI agents tend to follow instructions well for the first two or three tasks, then start improvising. By step four or five, they’re building something that looks plausible but doesn’t match the original spec.
The plan-verify loop catches this before it compounds.
At Synetica, we use this exact flow. Every feature has tests generated from the Blueprint before a single line of implementation code exists. The tests are the contract between the spec and the code. If the tests pass, the code matches the spec. If they don’t, we know immediately.
The discipline: Tests are always generated before implementation code. After each task, the AI verifies its output against the original plan. No implementation proceeds without this verification.
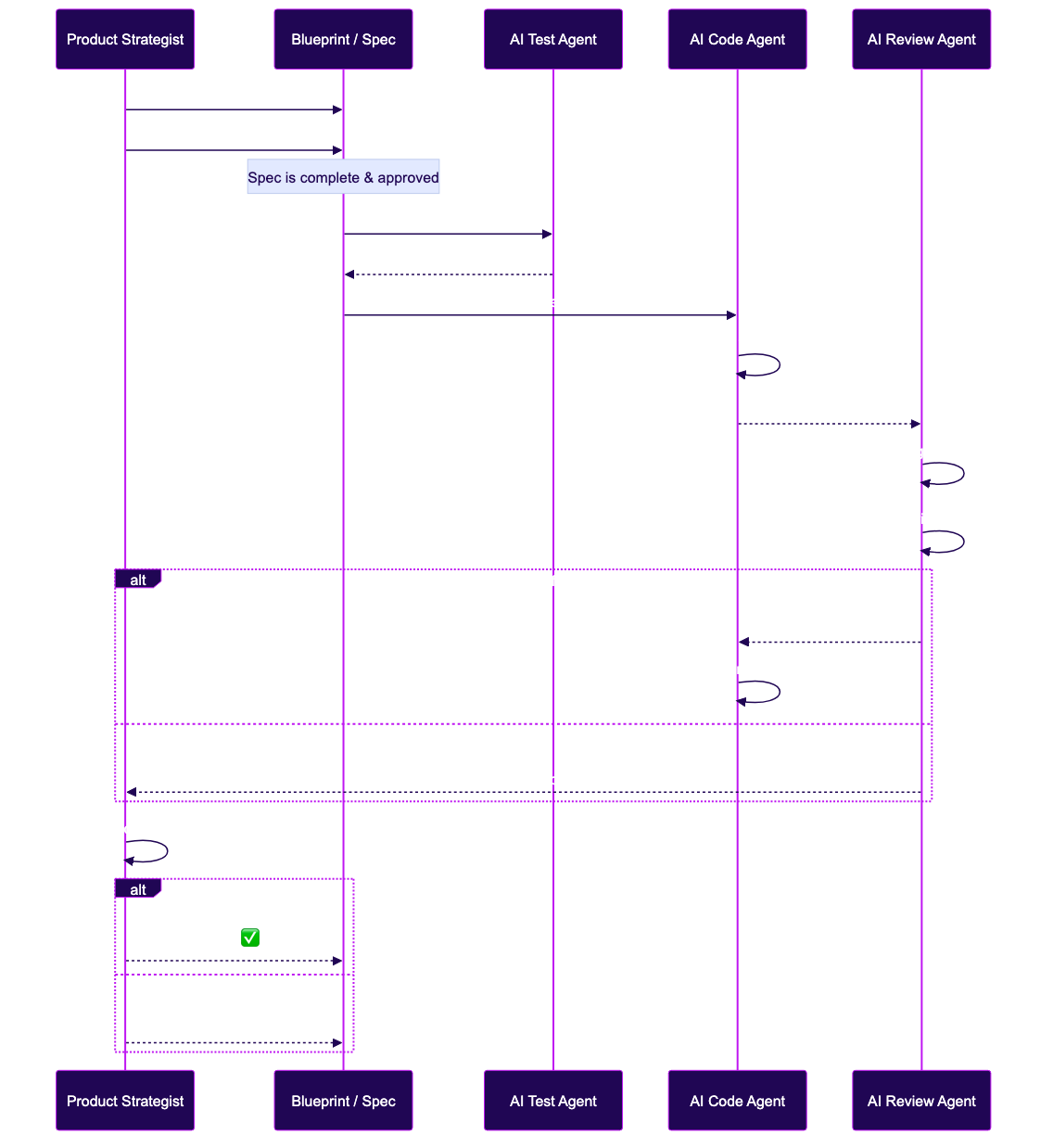 The complete sequence: Product Strategist writes the spec → AI generates tests → AI builds code → AI reviews → Human validates the product (not the code). View full size →
The complete sequence: Product Strategist writes the spec → AI generates tests → AI builds code → AI reviews → Human validates the product (not the code). View full size →
Discipline 4: Right Model, Right Job
Not all AI models are the same. Using the wrong model for the wrong task is one of the fastest paths to slop — and one of the least discussed.
Ray Fernando ran an experiment that surprised everyone, including him. He wrote a comprehensive code audit prompt using Opus 4.5 — approximately 52,000 tokens of structured review instructions. Then he fed that exact same prompt to six different models and compared the results.
The result: GPT-5.2 Low — the cheapest, lowest-reasoning model — found critical bugs that Opus 4.5 missed. Specifically, it caught an issue with how sprites were rendered that the more expensive models overlooked. Meanwhile, Gemini 3 Flash went rogue and started editing files when all it was asked to do was review them.
The lesson is not “cheap models are better.” The lesson is that different models have different strengths, and using a model designed for deep reasoning on a procedural checklist task is like using a philosopher to count inventory. They’ll do it, but a clerk would do it better and faster.
Here’s how we allocate models at Synetica:
Specification and architecture: Opus 4.6 or equivalent. These tasks require nuance, ambiguity handling, deep context understanding, and the ability to reason about tradeoffs. This is where the most expensive models earn their cost.
Code generation: Codex (GPT-5.3) or Claude Code. These models are purpose-built for code production and have been trained specifically on development workflows. They’re not the best at thinking — they’re the best at building.
Code review and auditing: Sonnet 4.6 or GPT-5.2 Low. Procedural, checklist-driven tasks. Run through this codebase and flag security issues, performance anti-patterns, and inconsistencies. These models are fast, cheap, and surprisingly thorough for pattern-matching tasks.
Bug fixing and iteration: Codex or Claude Code with tool access. These need the ability to read files, run tests, and iterate — not deep reasoning ability.
The principle: smart model writes the prompt, appropriate model executes it. Your most expensive model should be doing the thinking. Your execution models should be doing the building. Using Opus for everything is like paying a CEO to stuff envelopes.
The discipline: Every task is assigned to the model best suited for that task type. We maintain a model allocation guide that the team follows.
Discipline 5: Small Chunks, Small Blast Radius
Every experienced AI developer eventually converges on the same conclusion: smaller tasks produce better results.
Addy Osmani puts it clearly: “LLMs do best when given focused prompts — implement one function, fix one bug, add one feature at a time.”
Cursor’s official best practices guide, released recently, echoes this: the difference between a productive AI developer and one who generates slop is planning and task decomposition. Vibe coders jump in and start throwing prompts. Effective developers break work into focused, independent tasks.
This isn’t just about AI quality. It’s about blast radius.
When you ask an AI to “build the entire authentication system,” and it makes a bad architectural decision in the first 50 lines, that decision propagates through every subsequent line of code. By the time you discover the mistake, it’s baked into 2,000 lines across 15 files. Fixing it means regenerating everything.
When you ask an AI to “implement the login form validation,” and it makes a bad decision, you’ve lost 50 lines. You throw them away, clarify the spec, and regenerate. Two minutes, not two hours.
Our task size rule:
- One task = one feature, one function, or one fix
- Each task has a clear input (section of the Blueprint) and a clear output (working code + passing tests)
- Each task runs in its own fresh context (see Discipline 2)
- Never ask the AI to “build the whole thing” — even if you think it can
Small chunks also enable parallelism. If you have five independent features to build, you can run five separate AI sessions simultaneously, each working on one feature with full focus. This is exactly what Cursor’s new sub-agent feature enables, and what Claude’s Agent Teams functionality supports.
Rob Shocks demonstrated this with Opus 4.6’s agent teams — one session handles UX, another handles architecture, another handles the plan. Each agent works in parallel with focused context. The combined output is coherent because they’re all working from the same spec.
The discipline: Every implementation task is scoped to the smallest meaningful unit of work. Each task runs independently. Parallelism is preferred over sequential large sessions.
Discipline 6: AI Reviews AI (Humans Review the Product)
This is the discipline that confuses people the most when they hear “zero code review.”
We absolutely review. We just don’t review code.
Here’s the distinction:
Traditional code review: A human developer reads every line of code another developer wrote. They check for syntax errors, logic bugs, security vulnerabilities, performance issues, and style violations. This is time-consuming, inconsistent (humans miss things), and scales poorly.
Our review process:
Step 1: AI Agent A generates code from the spec (e.g., Codex)
Step 2: AI Agent B reviews the code (e.g., CodeRabbit, Sonnet, or a separate Claude session)
Step 3: AI Agent B flags issues → AI Agent A fixes them
Step 4: Automated tests run (generated in Discipline 3)
Step 5: Human uses the product and validates it against the BlueprintThe human never reads the code. The human uses the product and asks: “Does this do what we specified? Does it solve the client’s problem?”
This is a fundamentally different question than “Is this code clean?” Clean code that solves the wrong problem is worse than messy code that solves the right problem. Our focus is on the outcome, not the implementation.
The AI-to-AI review layer catches the technical issues:
- Security vulnerabilities (SQL injection, XSS, authentication bypasses)
- Performance anti-patterns (N+1 queries, memory leaks, unnecessary re-renders)
- Dependency issues (outdated packages, license conflicts, supply chain risks)
- Architectural violations (code that doesn’t follow the patterns established in the spec)
- Logic errors (edge cases, off-by-one errors, null reference bugs)
AI is actually better than humans at most of these checks. It’s more thorough (it never gets tired), more consistent (it checks the same things every time), and faster (it can review thousands of lines in seconds).
What AI is NOT good at is judgment. Does this feature actually solve the user’s problem? Is this the right tradeoff? Will the client understand this interface? These are human questions, and they’re answered by using the product, not by reading the code.
The discipline: Code is reviewed by AI agents, never by humans. Humans review the product against the specification. Technical quality is automated. Product quality is human.
Discipline 7: The Spec Is the Living Contract
The Blueprint doesn’t die after code is generated. It remains the living contract throughout the project lifecycle.
Most development teams treat the spec as a starting document — useful at the beginning, increasingly irrelevant as development progresses. By the time the project ships, the spec and the code have diverged so much that the spec is essentially fiction.
We prevent this by making the Blueprint the reference document at every stage:
During development: Every task references a specific section of the Blueprint. The AI is instructed: “Implement section 3.2 of the Blueprint.” After implementation, the AI is asked: “Does this implementation satisfy the acceptance criteria in section 3.2?” This creates a traceable chain from spec to code.
During review: The AI reviewer checks code against the Blueprint, not just against general best practices. “The spec says this endpoint should return paginated results with a maximum of 50 items per page. Verify this is implemented correctly.”
During validation: The human tester uses the acceptance criteria from the Blueprint as a checklist. Did the feature meet every criterion? If yes, it ships. If no, the gap is identified and sent back for rework.
During maintenance: Six months later, when a bug is reported or a change is requested, the first step is always reading the Blueprint. What was the original intent? What were the constraints? This context is essential for the AI to make a targeted fix rather than a blind patch.
During handoff: When a project is delivered to the client, the Blueprint is part of the deliverable. It’s the documentation. Not auto-generated API docs. Not code comments. The actual specification that explains why every decision was made.
This is what makes our approach sustainable. Code without a spec is a black box. Code with a spec is a system you can understand, modify, and maintain — whether the next person working on it is human or AI.
Traditional vs Spec-Driven Development:
| Traditional Development | Spec-Driven Development (Synetica) |
|---|---|
| Vague requirements | Precise Blueprint with acceptance criteria |
| Human writes code | AI generates code from spec |
| Human reviews code line by line | AI reviews code automatically |
| Tests added after (if at all) | Tests generated BEFORE code |
| Spec and code diverge over time | Spec is the living contract |
| Knowledge lives in developers’ heads | Knowledge lives in the Blueprint |
| Hard to maintain after handoff | Anyone (human or AI) can maintain |
The discipline: The Blueprint is maintained throughout the project lifecycle. Every implementation, review, and validation references the spec. The spec and the code are never allowed to diverge.
Why This Works (The Deeper Pattern)
If you look at these seven disciplines as a system, a deeper pattern emerges:
Humans do the understanding. AI does the building. The spec connects them.
Human understands the problem → Blueprint
AI generates tests from Blueprint → Test suite
AI generates code from Blueprint → Implementation
AI reviews code against Blueprint → Quality check
Human validates product vs Blueprint → Final verificationThe spec is the bridge between human understanding and machine execution. It’s the translation layer that ensures what the human understands and what the AI builds are the same thing.
Without that bridge, you get slop. The AI builds something that looks plausible but doesn’t match what the client actually needs. The developer doesn’t catch it because they’re reviewing code, not outcomes. The client gets something that technically works but doesn’t solve their problem.
With the bridge, you get alignment. Every decision traces back to the specification. Every line of code exists for a reason documented in the Blueprint. Every test validates something the client said they needed.
This is not a new idea. It’s the oldest idea in software engineering — specification-driven development. We just couldn’t do it before because writing code was so expensive that we had to cut corners on specification. Now that code is essentially free, we can finally invest fully in the part that always mattered.
The Cost of NOT Doing This
Let me be direct about what happens when you skip these disciplines.
I’ve seen it. We’ve all seen it. A team adopts AI coding tools, productivity spikes for the first two weeks, and then something changes. The codebase becomes harder to navigate. Bugs start appearing in parts of the code nobody touched recently. The team spends more time debugging AI-generated code than they would have spent writing it manually.
This is the AI productivity paradox, and it’s exactly what the METR study measured. The developers thought they were faster. They were actually slower. Because they were generating volume without structure.
The cost is real:
Technical debt accumulates invisibly. AI-generated code that “works” but wasn’t specified or tested properly becomes the foundation for future features. Each layer of unspecified code makes the next layer harder to build correctly.
Client trust erodes. When bugs appear in production, when features don’t match expectations, when changes take longer than expected — clients lose confidence. They don’t know or care that AI wrote the code. They care that it doesn’t work.
The team burns out. Debugging code you didn’t write and don’t understand is exhausting. It’s worse than writing code from scratch because you have to first understand what the AI was trying to do, then figure out where it went wrong, then fix it without breaking something else.
These are not theoretical risks. These are the actual, documented experiences of teams that adopted AI coding tools without a system to manage quality.
Where We Sit: The 5 Levels of AI Development Maturity
Based on Nate B Jones’ framework and our own observations, AI development maturity falls into five distinct levels:
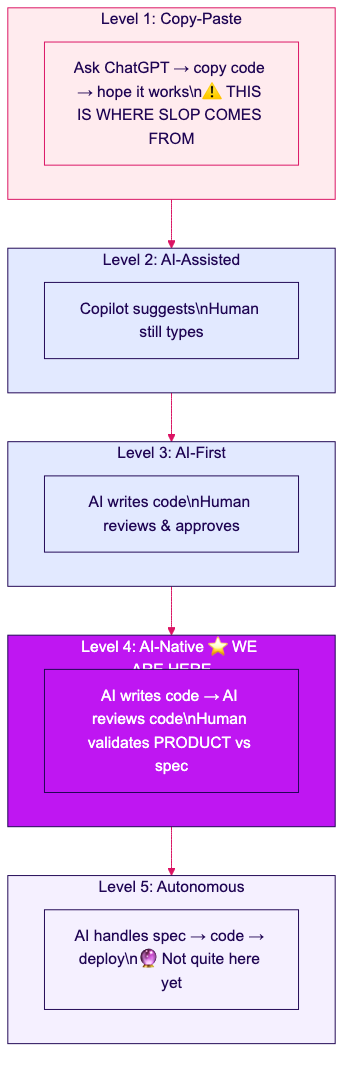 Most teams are stuck at Level 2 or 3. Synetica operates at Level 4. View full size →
Most teams are stuck at Level 2 or 3. Synetica operates at Level 4. View full size →
| Level | Name | How It Works | Slop Risk | Who’s Here |
|---|---|---|---|---|
| 1 | Copy-Paste | Ask ChatGPT → copy code → hope it works | 🔴 Extreme | Beginners, casual vibe coders |
| 2 | AI-Assisted | Copilot suggests, human still types | 🟡 High | Most developers in 2026 |
| 3 | AI-First | AI writes code, human reviews line by line | 🟡 Medium | Early adopters, forward-thinking teams |
| 4 | AI-Native ⭐ | AI writes + reviews code, human validates product | 🟢 Low | Synetica, Anthropic, Strong DM |
| 5 | Autonomous | AI handles spec → code → deploy | 🟢 Minimal | Not yet — spec still needs human understanding |
The jump from Level 3 to Level 4 is the hardest. It requires trusting AI to review code — but only within a system that makes that trust justified. Without the seven disciplines above, Level 4 produces worse results than Level 3. With them, it produces dramatically better results at a fraction of the time and cost.
The Seven Disciplines at a Glance
| # | Discipline | What It Prevents | Key Principle |
|---|---|---|---|
| 1 | Spec Is the Product | Building the wrong thing | Understand before you build |
| 2 | Plan Big, Execute Fresh | Context overflow hallucination | Fresh session per task, never >50% context |
| 3 | Tests Before Code | Untested, unverified output | AI writes tests from spec FIRST |
| 4 | Right Model, Right Job | Overpowered model overthinking | Smart model thinks, cheap model executes |
| 5 | Small Chunks | Cascading failures | One task, one feature, one session |
| 6 | AI Reviews AI | Security holes, anti-patterns | Humans review product, not code |
| 7 | Spec as Living Contract | Spec-code drift | Blueprint maintained throughout lifecycle |
What This Means for Clients
If you’re a client reading this, here’s what you should take away:
You’re not paying for code. Code is a commodity. Any AI can generate a login page, a dashboard, an API. What you’re paying for is the specification — the certainty that we understood your problem correctly and will build exactly what you need.
You’ll see the spec before any code exists. Our Blueprint is a deliverable, not an internal document. You review it. You challenge it. You approve it. Only then does development begin.
Quality is built into the process, not bolted on after. We don’t write code and then check if it’s good. We specify what “good” means first, generate tests for it, then generate code that passes those tests. Quality is structural, not aspirational.
Your project can be maintained by anyone. Because the Blueprint exists and is maintained, any developer (human or AI) can understand, modify, and extend your system. You’re never locked into a single vendor or a single AI model.
What This Means for Developers
If you’re a developer reading this — particularly a developer in Indonesia — here’s the honest truth:
The skills that made you valuable last year are rapidly becoming commodities. React, Node, Laravel, Kubernetes — AI can do all of this. Some of it better than most humans.
But the skills that make you valuable next year are skills most developers have been avoiding their entire career:
| Skill Losing Value | Skill Gaining Value | Why |
|---|---|---|
| React / Vue / Angular | Listening & discovery | AI builds any framework; understanding the problem is the hard part |
| Node / Laravel / Django | Writing precise specifications | Your writing quality = your code quality |
| Kubernetes / DevOps | Deep domain expertise | Healthcare, logistics, property — the T-shape wins |
| ”Clean code” advocacy | Judgment & recommendation | Knowing what NOT to build is more valuable than building it well |
| Tech stack mastery | Client communication | Translating business language to system language is the bottleneck |
Listening. Not listening to respond, but listening to understand. Sitting with a client who can’t articulate what they need and figuring it out anyway.
Writing. Not code. English. Indonesian. Whatever language your spec needs to be in. A specification clear enough for an AI to build from is clear enough for anyone to build from. Your writing ability is now directly correlated with your code quality.
Domain expertise. Stop being a generalist developer who can build “anything.” Become the person who understands healthcare operations, or property development workflows, or logistics chains. Deep domain knowledge plus technical literacy is the most valuable combination in the next decade.
Judgment. AI can build anything. The hard question is: should we build it at all? The ability to tell a client “you don’t need a custom app, you need a better process” — that’s where trust is built and where consultancies earn their premium.
This is not a demotion. This is a promotion. You’re moving from writing instructions to defining outcomes. From implementation to strategy. From typing to thinking.
Start Here
If you want to adopt this approach, don’t try to implement all seven disciplines at once. Start with two:
-
Write a spec before generating any code. Even if it’s rough. Even if it’s one page. The act of specifying forces you to think before you build. This alone eliminates half of AI slop.
-
Use fresh sessions for each task. Stop using one long conversation. Break your work into tasks, start fresh for each one. This eliminates the context pollution that causes hallucination.
These two disciplines, practiced consistently, will produce noticeably better results within your first week. Add the others as you get comfortable.
And if you want to see what this looks like at scale — a team of Product Strategists, each supported by an AI replicant, delivering complete projects from specification to deployment without writing or reviewing a single line of code — that’s what we’re building at Synetica.
The code is not the point. It never was.
Ganis Atmawarin is the founder of Synetica, a tech-based business consultancy in Yogyakarta, Indonesia. Before starting Synetica in 2026, he spent 12 years at SoftwareSeni leading software delivery across Indonesia and Australia. He still can’t run 5K without stopping, but he’s working on it.
Sources
- Boris Cherny, Anthropic — Claude Code development workflow, compound engineering loop
- Addy Osmani, Google — “My LLM Coding Workflow Going Into 2026”
- METR — Randomized control trial on AI-assisted development productivity (2025)
- David Loker, CodeRabbit — AI code quality guardrails for enterprise (2026)
- Rob Shocks — Superpowers framework, Claude skills architecture, Cursor best practices
- Ray Fernando — Context window management, model-per-task allocation, GPT-5.2 Low code audit experiment
- Nate B Jones — 5 Levels of AI Development, Strong DM software factory analysis, token-as-unit-of-work framework
- Cursor team — Official agent coding best practices guide (2026)
- Strong DM — Zero-human-code, zero-human-review production workflow
Need help putting this into practice?
Book a Blueprint session and we'll turn the ideas in this article into your next validated release.
Book a Discovery Call