Metodologi
Cara Kami Kirim Software Tanpa AI Slop
Tiga bulan terakhir, saya membangun konsultan software di mana nggak ada yang nulis kode.
Bukan “kami nulis kode lebih sedikit.” Bukan “AI bantu kami coding lebih cepat.” Nggak ada yang nulis kode. Nggak ada yang review kode baris per baris. AI yang kerjakan semuanya.
Kalau saya cerita ini ke orang, reaksinya cuma dua. Pertama, semangat — akhirnya ada yang paham. Kedua, horor — kok bisa kirim kode AI yang nggak di-review ke production?
Dua-duanya meleset dari intinya.
Kami bukan nekat. Bukan cowboy vibe coding yang lempar prompt ke Claude terus kirim apa pun yang keluar. Kami membangun sebuah sistem — sebuah metodologi — yang mencegah hal yang paling dikhawatirkan semua orang di industri ini sekarang: AI slop.
Artikel ini tentang sistem itu. Panjang. Detail. Karena kualitas itu hidup di detail.
Masalah Slop Itu Nyata
Mari kita jujur soal masalahnya.
AI slop adalah apa yang terjadi kalau kamu generate kode tanpa struktur. Kamu minta ChatGPT buatkan dashboard, hasilnya kelihatan keren, kamu kirim ke production. Tiga minggu kemudian, customer nemuin bug. Kamu minta AI perbaiki bug-nya. Malah muncul dua bug baru. Kamu minta perbaiki lagi. Codebase jadi tumpukan patch di atas patch, yang masing-masing digenerate oleh AI yang nggak ingat kenapa layer sebelumnya ada.
Ini bukan teori. Ini terjadi secara masif sekarang, di seluruh industri.
 Alur pengembangan Synetica: pemahaman mengalir ke spesifikasi, spesifikasi menggerakkan eksekusi AI, manusia memvalidasi hasilnya — bukan kodenya. Lihat ukuran penuh →
Alur pengembangan Synetica: pemahaman mengalir ke spesifikasi, spesifikasi menggerakkan eksekusi AI, manusia memvalidasi hasilnya — bukan kodenya. Lihat ukuran penuh →
CodeRabbit, platform AI code review, menerbitkan laporan 2026 yang menyebut ini tahun di mana enterprise harus punya “percakapan yang lebih serius tentang kualitas, atribusi, dan tata kelola” kode yang dihasilkan AI. Peningkatan produktivitas memang nyata — tapi utang teknis yang menumpuk diam-diam di bawahnya juga nyata.
METR, sebuah organisasi riset, menjalankan randomized control trial di 2025. Mereka menemukan bahwa developer berpengalaman yang menggunakan tools AI membutuhkan waktu 19% lebih lama untuk menyelesaikan tugas dibanding developer yang bekerja tanpa AI. Bagian yang nggak enak? Para developer itu percaya mereka 24% lebih cepat. Mereka salah — baik arahnya maupun besarannya.
Kok bisa? Karena AI bikin kamu merasa produktif. Token mengalir. Kode muncul. Layar terisi. Tapi merasa produktif dan benar-benar produktif itu dua hal berbeda. AI generate kode dengan cepat, tapi manusianya menghabiskan lebih banyak waktu debug, memahami, dan memperbaiki output AI daripada kalau mereka nulis sendiri dari awal.
Ini jebakan slop. Kecepatan tanpa struktur menghasilkan volume tanpa kualitas.
Tapi — dan ini bagian yang penting — riset yang sama juga menunjukkan bahwa tim tertentu, dengan workflow tertentu, mencapai hasil yang luar biasa. Di Anthropic, 90% kode Claude Code ditulis oleh Claude Code itu sendiri. Boris Cherny, yang memimpin proyek ini, sudah berbulan-bulan nggak nulis kode secara personal. Di perusahaan bernama Strong DM, tiga engineer menjalankan apa yang mereka sebut “software factory.” Dua prinsip inti mereka:
- Kode tidak boleh ditulis oleh manusia.
- Kode tidak boleh di-review oleh manusia.
Tiga engineer. Nggak ada yang nulis kode. Nggak ada yang review kode. Sistemnya adalah sekumpulan AI agent yang diorkestrasi oleh file spesifikasi markdown. Manusianya nulis spec dan evaluasi hasilnya. Mesinnya mengerjakan semua yang di antaranya.
Jadi pertanyaannya bukan apakah AI bisa menghasilkan kode berkualitas. Jelas bisa. Pertanyaannya: apa bedanya tim yang kirim kode AI yang bersih dengan tim yang kirim slop?
Jawabannya adalah sistem di sekitar AI-nya, bukan AI-nya sendiri.
Matriks Slop vs Kualitas:
| Struktur Tinggi | Struktur Rendah | |
|---|---|---|
| Pakai AI | ✅ Kualitas di skala besar (Synetica) | ⚠️ AI Slop (vibe coding) |
| Tanpa AI | 🐢 Kualitas tapi lambat (tradisional) | 💥 Kekacauan (cowboy coding) |
Pertanyaannya bukan “haruskah kita pakai AI?” — tapi “apakah kita punya struktur untuk pakai AI dengan benar?”
Sistem Kami: Tujuh Disiplin
Kami nggak menyebutnya “aturan” atau “best practice.” Kami menyebutnya disiplin, karena memang itu yang dibutuhkan. Masing-masing adalah pilihan sadar untuk melambat di momen tertentu supaya keseluruhan proses berjalan lebih cepat dan menghasilkan output yang lebih baik.
Disiplin 1: Spesifikasi Adalah Produknya
Ini fondasi dari semua yang kami kerjakan di Synetica. Datang dari keyakinan yang sudah saya pegang selama 15 tahun tapi baru bisa dieksekusi sekarang: nilai di pengembangan software itu bukan pernah di coding-nya. Selalu di memahami masalahnya.
Saya menulis ini dengan detail di “Kode Bukan Lagi Intinya.” Versi pendeknya: selama satu dekade, industri software Indonesia (dan jujur, global) mengenakan tarif ke klien untuk jam kerja developer. Enam orang, enam bulan, seratus juta rupiah. Tapi sebagian besar nilainya terdelivery di dua minggu pertama — saat seseorang benar-benar duduk dan memahami apa yang klien butuhkan.
Lima setengah bulan sisanya? Itu proses building. Lambat. Dengan miskomunikasi. Dengan requirement yang bergeser. Dengan code review yang menangkap syntax tapi luput menangkap intent.
AI baru saja membuat proses building itu gratis. Artinya satu-satunya hal yang layak dibayar adalah pemahamannya.
Di Synetica, kami menangkap pemahaman itu dalam apa yang kami sebut Blueprint — spesifikasi komprehensif yang cukup detail untuk AI agent bangun tanpa ambiguitas. Blueprint mencakup:
- Masalah yang sebenarnya — bukan apa yang klien minta, tapi apa yang mereka benar-benar butuhkan. Ini seringkali berbeda. Klien bilang “kami butuh CRM.” Yang sebenarnya mereka butuhkan adalah cara supaya lead nggak hilang antara sales call dan follow-up karena tiga departemen nggak saling bicara.
- Batasan sistem — apa yang masuk scope, apa yang eksplisit di luar scope, dan apa yang jadi change request di masa depan. Ini kritis karena AI agent dengan senang hati akan membangun hal yang nggak kamu minta kalau kamu nggak bilang jangan.
- Arsitektur data — entitas, relasi, constraint, aturan validasi. Bukan sketsa kasar. Spesifikasi presisi yang nggak menyisakan ruang bagi AI untuk berasumsi.
- User flow — langkah per langkah, termasuk edge case yang merusak kebanyakan software. Apa yang terjadi kalau user memasukkan data yang nggak valid? Apa yang terjadi kalau dua user mencoba approve hal yang sama secara bersamaan? Apa yang terjadi kalau koneksi putus?
- Kriteria penerimaan — kondisi yang bisa diukur dan diuji untuk “selesai.” Bukan “harusnya jalan.” Tapi “ketika user submit form dengan data valid, sistem harus menyimpan record dan redirect ke dashboard dalam 2 detik.”
- Strategi testing — apa yang ditest, bagaimana, dan kapan. Ini bukan tambahan di akhir. Ini bagian dari spec.
Addy Osmani, engineering leader senior di Google, mendeskripsikan pendekatan ini sebagai “waterfall dalam 15 menit” — fase perencanaan terstruktur yang cepat yang membuat semua hal di downstream lebih bersih. Observasinya: punya spec dan rencana yang jelas berarti ketika kamu melepaskan code generation, baik manusia maupun AI tahu persis apa yang sedang dibangun dan kenapa.
Kami menemukan bahwa investasi di spesifikasi mengeliminasi sekitar 80% rework yang biasanya datang dari AI yang salah memahami intent. Spec-nya nggak memperlambat kami. Justru itulah yang membuat segalanya cepat.
Disiplinnya: Nggak ada kode yang di-generate sampai Blueprint-nya selesai. Tanpa pengecualian. Kalau spec-nya masih bolong, kami kembali ke klien, bukan ke AI.
Disiplin 2: Rencanakan Besar, Eksekusi Segar
Ini disiplin teknis yang paling berdampak dalam praktik kami, dan datang dari observasi sederhana tentang cara kerja model AI.
Ray Fernando, yang menjalankan banyak AI agent di Mac Mini dan sudah banyak bereksperimen dengan context window, mengidentifikasi apa yang dia sebut “hallucination threshold.” Ketika sesi coding melampaui sekitar 50% dari context window model, kualitas output mulai menurun. AI-nya nggak jadi malas — tapi jadi terdistraksi. Semua riwayat percakapan, semua kode yang sudah di-generate, semua koreksi bolak-balik — semua itu jadi noise yang bersaing dengan tugas yang sebenarnya.
Fernando mendemonstrasikan ini secara dramatis: dia punya sesi planning yang berjalan di 93.000 token dan mau mulai implementasi. Dia sadar kalau mulai coding di sesi yang sama, context-nya akan langsung penuh dan kualitas bakal anjlok. Sebaliknya, dia ekspor rencana-nya, mulai sesi baru untuk setiap tugas implementasi, dan mengirimkan animasi sprite lengkap untuk lima karakter game dalam waktu kurang dari satu jam.
AI yang sama. Model yang sama. Kapabilitas yang sama. Satu-satunya perbedaan adalah context yang segar.
Begini cara kami menerapkannya:
Fase 1: Perencanaan (satu sesi mendalam) Kami load Blueprint, diskusikan arsitektur, buat keputusan desain, dan menghasilkan task breakdown terstruktur. Sesi ini boleh panjang — 80K, 90K, bahkan 100K token nggak masalah karena kami sedang berpikir, bukan coding. Output sesi ini adalah dokumen rencana tugas.
Fase 2: Eksekusi (banyak sesi segar) Setiap tugas dari rencana mendapat sesi segar sendiri. AI hanya menerima tiga hal: bagian Blueprint yang relevan, kode existing yang relevan, dan deskripsi tugasnya. Tidak ada lagi. Tidak ada riwayat tugas sebelumnya. Tidak ada obrolan tentang cuaca. Hanya context yang bersih dan terfokus.
Ini kontra-intuitif. Kebanyakan orang berpikir menjaga AI di satu sesi panjang memberinya “lebih banyak context” dan karenanya hasil yang lebih baik. Kenyataannya kebalikannya. AI yang terfokus dengan 20K token context relevan mengalahkan AI yang terdistraksi dengan 90K token context campuran setiap saat.
Disiplinnya: Perencanaan dan eksekusi terjadi di sesi terpisah. Setiap tugas implementasi dimulai dengan context window yang segar. Tanpa pengecualian.
Disiplin 3: Test Dulu, Baru Kode (Dan AI yang Nulis Dua-duanya)
Test-driven development sudah dikhotbahkan selama puluhan tahun. Kebanyakan tim masih nggak melakukannya. Alasannya karena menulis test itu membosankan, dan developer — karena manusia — secara alami tertarik ke pekerjaan yang menarik (menulis fitur) dan menjauhi pekerjaan yang membosankan (menulis test).
AI nggak punya bias ini. AI dengan senang hati menulis test seharian.
Framework Superpowers, yang semakin populer di komunitas Claude Code dan Cursor, memformalkan ini jadi urutan yang ketat:
1. Baca spec → 2. Generate test dari spec → 3. Tulis kode untuk lulus test → 4. Verifikasi test lulus → 5. Cek ulang terhadap rencana awalInsight kritis ada di langkah 2: AI menulis test langsung dari spesifikasi, sebelum menulis kode implementasi apa pun. Ini berarti test-nya merefleksikan apa yang seharusnya terjadi menurut spec, bukan apa yang kebetulan dilakukan kode. Bedanya antara “apakah kode ini jalan?” dan “apakah kode ini melakukan apa yang kita spesifikasikan?”
Langkah 5 sama pentingnya, dan datang dari pekerjaan Rob Shocks di workflow pengembangan. Setelah setiap tugas implementasi, AI kembali ke rencana awal dan memverifikasi bahwa kode-nya cocok dengan kriteria sukses yang didefinisikan di tahap perencanaan. Ini menangkap failure mode paling umum di pengembangan berbantuan AI: plan drift. AI agent cenderung mengikuti instruksi dengan baik untuk dua atau tiga tugas pertama, lalu mulai improvisasi. Di langkah empat atau lima, mereka membangun sesuatu yang terlihat masuk akal tapi nggak cocok dengan spec aslinya.
Loop plan-verify menangkap ini sebelum menumpuk.
Di Synetica, kami pakai flow ini persis. Setiap fitur punya test yang di-generate dari Blueprint sebelum satu baris kode implementasi ada. Test-test ini adalah kontrak antara spec dan kode. Kalau test lulus, kode cocok dengan spec. Kalau nggak, kami langsung tahu.
Disiplinnya: Test selalu di-generate sebelum kode implementasi. Setelah setiap tugas, AI memverifikasi output-nya terhadap rencana awal. Tidak ada implementasi yang berjalan tanpa verifikasi ini.
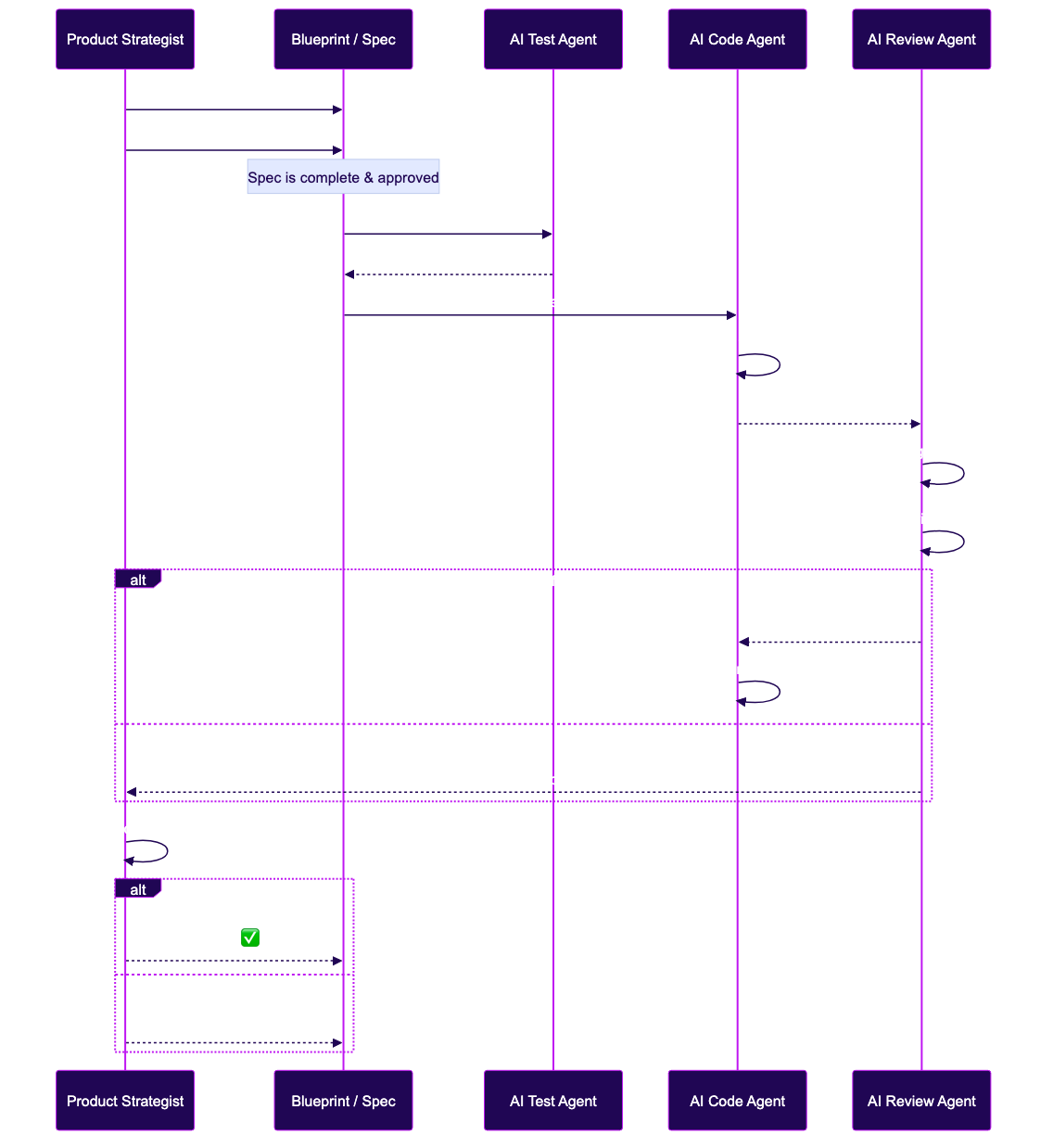 Urutan lengkap: Product Strategist menulis spec → AI generate test → AI bangun kode → AI review → Manusia memvalidasi produknya (bukan kodenya). Lihat ukuran penuh →
Urutan lengkap: Product Strategist menulis spec → AI generate test → AI bangun kode → AI review → Manusia memvalidasi produknya (bukan kodenya). Lihat ukuran penuh →
Disiplin 4: Model yang Tepat untuk Pekerjaan yang Tepat
Nggak semua model AI itu sama. Menggunakan model yang salah untuk tugas yang salah adalah salah satu jalan tercepat menuju slop — dan salah satu yang paling jarang dibahas.
Ray Fernando menjalankan eksperimen yang mengejutkan semua orang, termasuk dirinya sendiri. Dia menulis prompt code audit komprehensif menggunakan Opus 4.5 — kurang lebih 52.000 token instruksi review terstruktur. Lalu dia masukkan prompt yang sama persis ke enam model berbeda dan membandingkan hasilnya.
Hasilnya: GPT-5.2 Low — model termurah, dengan level reasoning terendah — menemukan bug kritis yang luput dari Opus 4.5. Secara spesifik, model ini menangkap masalah dengan cara sprite di-render yang terlewat oleh model-model yang lebih mahal. Sementara itu, Gemini 3 Flash malah ngaco dan mulai mengedit file padahal yang diminta cuma review.
Pelajarannya bukan “model murah lebih baik.” Pelajarannya adalah model yang berbeda punya kekuatan yang berbeda, dan menggunakan model yang dirancang untuk deep reasoning pada tugas checklist prosedural itu seperti menyuruh filsuf menghitung inventaris. Mereka bisa, tapi seorang admin akan melakukannya lebih baik dan lebih cepat.
Begini cara kami mengalokasikan model di Synetica:
Spesifikasi dan arsitektur: Opus 4.6 atau setara. Tugas-tugas ini membutuhkan nuansa, penanganan ambiguitas, pemahaman context yang dalam, dan kemampuan bernalar tentang tradeoff. Di sinilah model termahal membuktikan nilainya.
Code generation: Codex (GPT-5.3) atau Claude Code. Model-model ini dirancang khusus untuk produksi kode dan sudah dilatih spesifik pada workflow pengembangan. Mereka bukan yang terbaik dalam berpikir — tapi yang terbaik dalam membangun.
Code review dan auditing: Sonnet 4.6 atau GPT-5.2 Low. Tugas prosedural, berbasis checklist. Scan codebase ini dan tandai masalah keamanan, anti-pattern performa, dan inkonsistensi. Model-model ini cepat, murah, dan surprisingly teliti untuk tugas pattern-matching.
Bug fixing dan iterasi: Codex atau Claude Code dengan tool access. Yang dibutuhkan adalah kemampuan membaca file, menjalankan test, dan iterasi — bukan kemampuan deep reasoning.
Prinsipnya: model pintar yang nulis prompt, model yang tepat yang mengeksekusi. Model termahalmu harus mengerjakan thinking-nya. Model eksekusimu harus mengerjakan building-nya. Pakai Opus untuk semua hal itu seperti membayar CEO untuk masukin amplop.
Disiplinnya: Setiap tugas diassign ke model yang paling cocok untuk tipe tugas itu. Kami punya panduan alokasi model yang diikuti tim.
Disiplin 5: Potongan Kecil, Ledakan Kecil
Setiap AI developer berpengalaman akhirnya sampai pada kesimpulan yang sama: tugas yang lebih kecil menghasilkan output yang lebih baik.
Addy Osmani mengatakannya dengan jelas: “LLM bekerja paling baik kalau dikasih prompt yang terfokus — implementasi satu fungsi, perbaiki satu bug, tambahkan satu fitur per saat.”
Panduan best practice resmi Cursor, yang baru dirilis, menggemakan hal ini: perbedaan antara developer AI yang produktif dan yang menghasilkan slop adalah perencanaan dan dekomposisi tugas. Vibe coder langsung terjun dan mulai lempar prompt. Developer yang efektif memecah pekerjaan jadi tugas-tugas yang terfokus dan independen.
Ini bukan cuma soal kualitas AI. Ini soal blast radius.
Kalau kamu minta AI “bangun seluruh sistem autentikasi,” dan dia membuat keputusan arsitektur yang salah di 50 baris pertama, keputusan itu menyebar ke setiap baris kode setelahnya. Waktu kamu menemukan kesalahannya, itu sudah tertanam di 2.000 baris di 15 file. Memperbaikinya berarti regenerate semuanya.
Kalau kamu minta AI “implementasi validasi form login,” dan dia membuat keputusan yang salah, kamu kehilangan 50 baris. Kamu buang, perjelas spec-nya, dan regenerate. Dua menit, bukan dua jam.
Aturan ukuran tugas kami:
- Satu tugas = satu fitur, satu fungsi, atau satu perbaikan
- Setiap tugas punya input yang jelas (bagian dari Blueprint) dan output yang jelas (kode jalan + test lulus)
- Setiap tugas berjalan di context segar sendiri (lihat Disiplin 2)
- Jangan pernah minta AI “bangun semuanya” — meskipun dia bilang bisa
Potongan kecil juga memungkinkan paralelisme. Kalau kamu punya lima fitur independen yang harus dibangun, kamu bisa menjalankan lima sesi AI terpisah secara bersamaan, masing-masing mengerjakan satu fitur dengan fokus penuh.
Disiplinnya: Setiap tugas implementasi di-scope ke unit pekerjaan terkecil yang bermakna. Setiap tugas berjalan secara independen. Paralelisme lebih disukai daripada sesi besar yang berurutan.
Disiplin 6: AI Review AI (Manusia Review Produknya)
Ini disiplin yang paling membingungkan orang ketika mereka dengar “zero code review.”
Kami pasti review. Kami cuma nggak review kode.
Ini bedanya:
Code review tradisional: Seorang developer manusia membaca setiap baris kode yang ditulis developer lain. Mereka memeriksa syntax error, bug logika, kerentanan keamanan, masalah performa, dan pelanggaran style. Ini makan waktu, nggak konsisten (manusia melewatkan hal), dan nggak bisa di-scale.
Proses review kami:
Langkah 1: AI Agent A generate kode dari spec (misal Codex)
Langkah 2: AI Agent B review kode-nya (misal CodeRabbit, Sonnet, atau sesi Claude terpisah)
Langkah 3: AI Agent B menandai masalah → AI Agent A memperbaiki
Langkah 4: Automated test jalan (yang di-generate di Disiplin 3)
Langkah 5: Manusia menggunakan produknya dan memvalidasi terhadap BlueprintManusia nggak pernah membaca kode-nya. Manusia menggunakan produknya dan bertanya: “Apakah ini melakukan apa yang kita spesifikasikan? Apakah ini menyelesaikan masalah klien?”
Ini pertanyaan yang secara fundamental berbeda dari “Apakah kode ini bersih?” Kode bersih yang menyelesaikan masalah yang salah lebih buruk daripada kode berantakan yang menyelesaikan masalah yang benar. Fokus kami pada outcome, bukan implementasi.
Layer review AI-ke-AI menangkap masalah teknis:
- Kerentanan keamanan (SQL injection, XSS, authentication bypass)
- Anti-pattern performa (N+1 query, memory leak, re-render yang nggak perlu)
- Masalah dependency (paket yang outdated, konflik lisensi, risiko supply chain)
- Pelanggaran arsitektural (kode yang nggak mengikuti pattern yang ditetapkan di spec)
- Error logika (edge case, off-by-one error, null reference bug)
AI sebenarnya lebih baik daripada manusia di kebanyakan pengecekan ini. Lebih teliti (nggak pernah capek), lebih konsisten (memeriksa hal yang sama setiap kali), dan lebih cepat (bisa review ribuan baris dalam hitungan detik).
Yang AI TIDAK bagus adalah judgment. Apakah fitur ini benar-benar menyelesaikan masalah user? Apakah ini tradeoff yang tepat? Apakah klien akan memahami interface ini? Ini pertanyaan manusia, dan dijawab dengan menggunakan produknya, bukan membaca kodenya.
Disiplinnya: Kode di-review oleh AI agent, nggak pernah oleh manusia. Manusia review produknya terhadap spesifikasi. Kualitas teknis diotomasi. Kualitas produk itu urusan manusia.
Disiplin 7: Spec Adalah Kontrak yang Hidup
Blueprint nggak mati setelah kode di-generate. Ia tetap jadi kontrak yang hidup sepanjang lifecycle proyek.
Kebanyakan tim development memperlakukan spec sebagai dokumen pembuka — berguna di awal, semakin tidak relevan seiring development berjalan. Pada saat proyek rilis, spec dan kode sudah menyimpang begitu jauh sehingga spec-nya pada dasarnya fiksi.
Kami mencegah ini dengan menjadikan Blueprint sebagai dokumen referensi di setiap tahap:
Selama development: Setiap tugas merujuk bagian spesifik dari Blueprint. AI diinstruksikan: “Implementasi bagian 3.2 dari Blueprint.” Setelah implementasi, AI ditanya: “Apakah implementasi ini memenuhi kriteria penerimaan di bagian 3.2?” Ini menciptakan rantai yang bisa dilacak dari spec ke kode.
Selama review: AI reviewer memeriksa kode terhadap Blueprint, bukan hanya terhadap best practice umum. “Spec mengatakan endpoint ini harus mengembalikan hasil yang dipaginasi dengan maksimum 50 item per halaman. Verifikasi bahwa ini diimplementasi dengan benar.”
Selama validasi: Tester manusia menggunakan kriteria penerimaan dari Blueprint sebagai checklist. Apakah fiturnya memenuhi setiap kriteria? Kalau ya, kirim. Kalau nggak, gap-nya diidentifikasi dan dikirim balik untuk rework.
Selama maintenance: Enam bulan kemudian, kalau ada bug report atau permintaan perubahan, langkah pertama selalu membaca Blueprint. Apa intent aslinya? Apa constraint-nya? Context ini esensial supaya AI bisa membuat perbaikan yang terarah, bukan patch yang buta.
Selama handoff: Ketika proyek diserahkan ke klien, Blueprint adalah bagian dari deliverable. Itu dokumentasinya. Bukan auto-generated API docs. Bukan komentar kode. Spesifikasi aktual yang menjelaskan kenapa setiap keputusan dibuat.
Ini yang membuat pendekatan kami sustainable. Kode tanpa spec adalah kotak hitam. Kode dengan spec adalah sistem yang bisa kamu pahami, modifikasi, dan maintain — entah yang mengerjakan selanjutnya itu manusia atau AI.
Perbandingan Development Tradisional vs Berbasis Spec:
| Development Tradisional | Development Berbasis Spec (Synetica) |
|---|---|
| Requirement samar | Blueprint presisi dengan kriteria penerimaan |
| Manusia nulis kode | AI generate kode dari spec |
| Manusia review kode baris per baris | AI review kode secara otomatis |
| Test ditambah belakangan (kalau ada) | Test di-generate SEBELUM kode |
| Spec dan kode menyimpang seiring waktu | Spec adalah kontrak yang hidup |
| Knowledge hidup di kepala developer | Knowledge hidup di Blueprint |
| Sulit di-maintain setelah handoff | Siapa pun (manusia atau AI) bisa maintain |
Disiplinnya: Blueprint dijaga sepanjang lifecycle proyek. Setiap implementasi, review, dan validasi merujuk spec-nya. Spec dan kode tidak boleh dibiarkan menyimpang.
Kenapa Ini Berhasil (Pola yang Lebih Dalam)
Kalau kamu melihat tujuh disiplin ini sebagai sebuah sistem, ada pola yang lebih dalam:
Manusia yang memahami. AI yang membangun. Spec yang menghubungkan.
Manusia memahami masalah → Blueprint
AI generate test dari Blueprint → Test suite
AI generate kode dari Blueprint → Implementasi
AI review kode terhadap Blueprint → Quality check
Manusia validasi produk vs Blueprint → Verifikasi akhirSpec adalah jembatan antara pemahaman manusia dan eksekusi mesin. Ini layer translasi yang memastikan apa yang dipahami manusia dan apa yang dibangun AI itu hal yang sama.
Tanpa jembatan itu, kamu dapat slop. AI membangun sesuatu yang terlihat masuk akal tapi nggak cocok dengan yang sebenarnya dibutuhkan klien. Developer nggak menangkapnya karena mereka review kode, bukan outcome. Klien mendapat sesuatu yang secara teknis jalan tapi nggak menyelesaikan masalah mereka.
Dengan jembatan itu, kamu dapat alignment. Setiap keputusan bisa dilacak ke spesifikasi. Setiap baris kode ada karena alasan yang terdokumentasi di Blueprint. Setiap test memvalidasi sesuatu yang klien katakan mereka butuhkan.
Harga dari TIDAK Melakukan Ini
Saya mau langsung saja soal apa yang terjadi kalau kamu melewati disiplin-disiplin ini.
Saya sudah lihat. Kita semua sudah lihat. Sebuah tim mengadopsi AI coding tools, produktivitas melonjak dua minggu pertama, lalu sesuatu berubah. Codebase jadi lebih susah dinavigasi. Bug mulai muncul di bagian kode yang nggak disentuh siapa pun belakangan ini. Tim menghabiskan lebih banyak waktu debug kode AI daripada kalau mereka nulis manual.
Biayanya nyata:
Utang teknis menumpuk tanpa terlihat. Kode AI yang “jalan” tapi nggak di-spec atau di-test dengan benar jadi fondasi untuk fitur-fitur selanjutnya. Setiap layer kode tanpa spesifikasi membuat layer berikutnya lebih susah dibangun dengan benar.
Kepercayaan klien terkikis. Kalau bug muncul di production, kalau fitur nggak sesuai ekspektasi, kalau perubahan memakan waktu lebih lama dari seharusnya — klien kehilangan kepercayaan.
Tim-nya burnout. Debug kode yang nggak kamu tulis dan nggak kamu pahami itu melelahkan. Lebih buruk dari nulis kode dari awal karena kamu harus pertama memahami apa yang AI coba lakukan, lalu cari tahu di mana salahnya, lalu perbaiki tanpa merusak hal lain.
Di Mana Posisi Kami: 5 Level Maturitas Development AI
Berdasarkan framework Nate B Jones dan observasi kami sendiri:
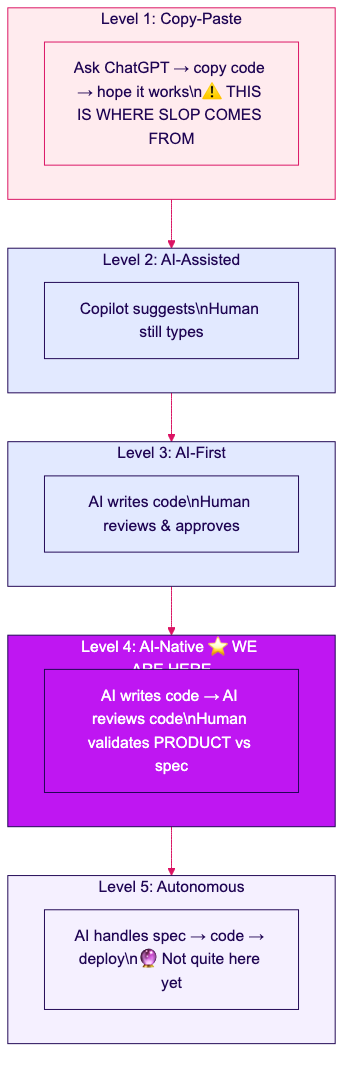 Kebanyakan tim terjebak di Level 2 atau 3. Synetica beroperasi di Level 4. Lihat ukuran penuh →
Kebanyakan tim terjebak di Level 2 atau 3. Synetica beroperasi di Level 4. Lihat ukuran penuh →
| Level | Nama | Cara Kerjanya | Risiko Slop | Siapa yang Ada di Sini |
|---|---|---|---|---|
| 1 | Copy-Paste | Tanya ChatGPT → copy kode → berharap jalan | 🔴 Ekstrem | Pemula, vibe coder kasual |
| 2 | AI-Assisted | Copilot menyarankan, manusia masih mengetik | 🟡 Tinggi | Kebanyakan developer di 2026 |
| 3 | AI-First | AI nulis kode, manusia review baris per baris | 🟡 Sedang | Early adopter, tim yang forward-thinking |
| 4 | AI-Native ⭐ | AI nulis + review kode, manusia validasi produk | 🟢 Rendah | Synetica, Anthropic, Strong DM |
| 5 | Autonomous | AI handle dari spec → kode → deploy | 🟢 Minimal | Belum sepenuhnya — spec masih butuh pemahaman manusia |
Tujuh Disiplin Sekilas
| # | Disiplin | Apa yang Dicegah | Prinsip Kunci |
|---|---|---|---|
| 1 | Spec Adalah Produknya | Membangun hal yang salah | Pahami dulu sebelum membangun |
| 2 | Rencana Besar, Eksekusi Segar | Halusinasi dari context overflow | Sesi segar per tugas, jangan >50% context |
| 3 | Test Dulu, Baru Kode | Output yang nggak teruji | AI nulis test dari spec DULU |
| 4 | Model Tepat, Tugas Tepat | Model overpowered yang overthink | Model pintar berpikir, model murah mengeksekusi |
| 5 | Potongan Kecil | Kegagalan berantai | Satu tugas, satu fitur, satu sesi |
| 6 | AI Review AI | Celah keamanan, anti-pattern | Manusia review produk, bukan kode |
| 7 | Spec sebagai Kontrak Hidup | Penyimpangan spec-kode | Blueprint dijaga sepanjang lifecycle |
Apa Artinya untuk Klien
Kalau kamu klien yang membaca ini, inilah yang perlu kamu bawa:
Kamu bukan bayar untuk kode. Kode itu komoditas. AI mana pun bisa generate halaman login, dashboard, API. Yang kamu bayar adalah spesifikasinya — kepastian bahwa kami memahami masalahmu dengan benar dan akan membangun persis apa yang kamu butuhkan.
Kamu akan lihat spec-nya sebelum kode apa pun ada. Blueprint kami adalah deliverable, bukan dokumen internal. Kamu review. Kamu tantang. Kamu setujui. Baru setelah itu development dimulai.
Kualitas dibangun ke dalam proses, bukan ditempel di akhir. Kami nggak nulis kode terus cek apakah bagus. Kami definisikan dulu apa artinya “bagus,” generate test untuk itu, lalu generate kode yang lulus test-test itu.
Proyekmu bisa di-maintain oleh siapa pun. Karena Blueprint ada dan dijaga, developer mana pun (manusia atau AI) bisa memahami, memodifikasi, dan mengembangkan sistemmu. Kamu nggak pernah terkunci di satu vendor.
Apa Artinya untuk Developer
Kalau kamu developer yang membaca ini — terutama developer di Indonesia — inilah kebenaran yang jujur:
Skill yang bikin kamu berharga tahun lalu sedang dengan cepat jadi komoditas. React, Node, Laravel, Kubernetes — AI bisa kerjakan semua ini. Beberapa di antaranya lebih baik dari kebanyakan manusia.
Tapi skill yang bikin kamu berharga tahun depan adalah skill yang kebanyakan developer hindari sepanjang karir mereka:
| Skill yang Nilainya Turun | Skill yang Nilainya Naik | Kenapa |
|---|---|---|
| React / Vue / Angular | Mendengarkan & discovery | AI bangun framework apa pun; memahami masalah itu bagian sulitnya |
| Node / Laravel / Django | Menulis spesifikasi yang presisi | Kualitas tulisanmu = kualitas kodemu |
| Kubernetes / DevOps | Keahlian domain yang dalam | Healthcare, logistik, properti — bentuk T yang menang |
| Advokasi “clean code” | Judgment & rekomendasi | Tahu apa yang TIDAK perlu dibangun lebih berharga daripada membangunnya dengan baik |
| Penguasaan tech stack | Komunikasi klien | Menerjemahkan bahasa bisnis ke bahasa sistem adalah bottleneck-nya |
Ini bukan demosi. Ini promosi. Kamu bergerak dari menulis instruksi ke mendefinisikan outcome. Dari implementasi ke strategi. Dari mengetik ke berpikir.
Mulai dari Sini
Kalau kamu mau mengadopsi pendekatan ini, jangan coba implementasi ketujuh disiplin sekaligus. Mulai dengan dua:
-
Tulis spec sebelum generate kode apa pun. Meskipun kasar. Meskipun cuma satu halaman. Tindakan menspesifikasi memaksamu berpikir sebelum membangun. Ini saja mengeliminasi setengah dari AI slop.
-
Gunakan sesi segar untuk setiap tugas. Berhenti pakai satu percakapan panjang. Pecah pekerjaanmu jadi tugas-tugas, mulai segar untuk masing-masing. Ini mengeliminasi polusi context yang menyebabkan halusinasi.
Dua disiplin ini, dipraktikkan secara konsisten, akan menghasilkan output yang terasa lebih baik dalam minggu pertamamu. Tambahkan yang lain seiring kamu nyaman.
Dan kalau kamu mau lihat seperti apa ini di skala besar — tim Product Strategist, masing-masing didukung AI replicant, mendelivery proyek lengkap dari spesifikasi sampai deployment tanpa menulis atau me-review satu baris kode pun — itulah yang sedang kami bangun di Synetica.
Kode bukan intinya. Memang nggak pernah.
Ganis Atmawarin adalah pendiri Synetica, konsultan bisnis berbasis teknologi di Yogyakarta, Indonesia. Sebelum memulai Synetica di 2026, dia menghabiskan 12 tahun di SoftwareSeni memimpin delivery software di Indonesia dan Australia. Dia masih belum bisa lari 5K tanpa berhenti, tapi sedang berusaha.
Sumber
- Boris Cherny, Anthropic — Workflow pengembangan Claude Code, compound engineering loop
- Addy Osmani, Google — “My LLM Coding Workflow Going Into 2026”
- METR — Randomized control trial pada produktivitas pengembangan berbantuan AI (2025)
- David Loker, CodeRabbit — AI code quality guardrails untuk enterprise (2026)
- Rob Shocks — Framework Superpowers, arsitektur skills Claude, best practice Cursor
- Ray Fernando — Manajemen context window, alokasi model per tugas, eksperimen code audit GPT-5.2 Low
- Nate B Jones — 5 Level AI Development, analisis software factory Strong DM, framework token-as-unit-of-work
- Tim Cursor — Panduan resmi best practice agent coding (2026)
- Strong DM — Workflow production zero-human-code, zero-human-review
Butuh bantuan menerapkan ini?
Pesan sesi Blueprint dan kami akan ubah ide di artikel ini jadi rilis tervalidasi berikutnya.
Jadwalkan Discovery Call